暗号化のお話 (3)
| 前へ << 暗号化のお話 (2) | 暗号化のお話 (5) >> 次へ |
署名の考え方
公開鍵暗号方式は、暗号化以外にも使い道があります。それが署名です。 署名とは「この文書は確かに私が書いたものであると証明できるもの」を指します。最初は以下のような状態です。送信者は
- 平文
- 送信者の公開鍵
- 送信者の秘密鍵
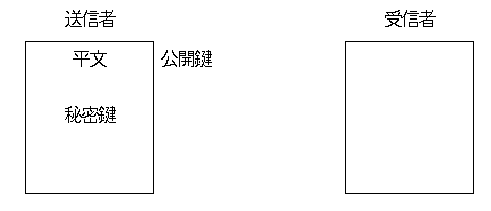 |
| 図 1: 署名の初期状態 |
- 送信者は、自分の秘密鍵で平文を暗号化します。
- 送信者は、「平文」と「暗号文」を受信者に送信します。
- 受信者は、送信者の公開鍵を取り寄せます。
- 受信者は、暗号文を「取り寄せた公開鍵」で復号化します。
- 受信者は、「平文」と「復号化して得られた平文」を比較します。 両者が一致すれば署名は正しいことがわかります。
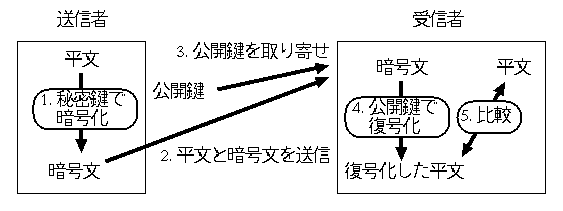 |
| 図 2: 署名の流れ |
「署名をしたところで盗聴できてしまうんでしょ? そんなものが役に立つの?」 と思われるかもしれませんが、使いどころは結構あります。
例えば このメール は FreeBSD Poject が発行したもので「bind8 にセキュリティホールがある」 という警告文書です。このメールが本物かどうかは 公開鍵 を使うことで検証できます。
ただし、上記の署名には以下のような欠点があります。
- 公開鍵暗号方式は遅い。平文全部を暗号化すると、かなりの時間がかかる。
- 平文と暗号文を送信すると、データ量が約 2倍になる。
ハッシュ
ハッシュは、以下のような特徴を持ちます。- 特徴1. 入力データに応じたハッシュ値を出力する。
- 特徴2. ハッシュ値から入力データを生成することはできない。
- 特徴3. 異なるデータ A と入力としたときハッシュ値 A' を出力するとしたら、 同じハッシュ値を生成するデータ B (データ A とは異なる入力) を探すのが困難。
% echo a | md5 60b725f10c9c85c70d97880dfe8191b3 ⇒ a のハッシュ値は 60b725f10c9c85c70d97880dfe8191b3 % echo hoge | md5 c59548c3c576228486a1f0037eb16a1b ⇒ hoge のハッシュ値は c59548c3c576228486a1f0037eb16a1b % echo hogehoge | md5 d9a3fdfc7ca17c47ed007bed5d2eb873 ⇒ hogehoge のハッシュ値は d9a3fdfc7ca17c47ed007bed5d2eb873 % echo hogehogehogehogehogehogehogehogehogehogehogehoge | md5 8bbbf93defbb56c80e90ada9bdca0498 ⇒ hoge…hoge のハッシュ値は 8bbbf93defbb56c80e90ada9bdca0498Linux などでは md5 ではなく md5sum という名前のコマンドの場合もあります。 また、OpenSSL がインストールされていれば、openssl dgst を使うこともできます。
% echo a | md5sum 60b725f10c9c85c70d97880dfe8191b3 % echo a | openssl dgst -md5 60b725f10c9c85c70d97880dfe8191b3どんな長さのデータを食わせても、出力は一定の長さです (md5 の出力は 16進数 32桁 = 128bit)。 長さに制限はありません。
MD5 はアルゴリズムがきっちり決まっているので、どの実装系で 実行しても同じ結果が得られます (MD5 の詳細は RFC 1321 を参照)。まぁ、実装ごとにハッシュ値が異なるようでは、 ハッシュとしての役目を果たせないのですが。
もう一度、ハッシュ関数の特徴を見てみましょう。
- 特徴1. 入力データに応じたハッシュ値を出力する。
- ⇒ これについては納得でしょう。上記の例では「a」「hoge」「hogehoge」 「hoge…hoge」を入力データとしていますが、 それぞれ異なるハッシュ値が生成されています (実際には「a」ではなく「a+改行コード」が入力データです)。
- 特徴2. ハッシュ値から入力データを生成することはできない。
-
⇒ 「hoge…hoge」の長さは、その
ハッシュ値の「8bbbf93defbb56c80e90ada9bdca0498」より明らかに長いです。
「hoge…hoge」よりも長い文字列はいくらでもあります。
しかし入力がいくら長くなっても出力は 128bit 固定です。
入力データサイズが 1MB でも 1GB でも 128bit 固定です。
これではハッシュ値から元のデータを復元するのはどう考えても無理です。
つまり、ハッシュは暗号化ではありません。 暗号化というのは復号できて始めて「暗号化」と呼べるのです。 元に戻せないものを暗号化とは呼びません。繰り返しますが、 ハッシュは暗号化ではありません。ハッシュはハッシュです。暗号化とは別物です。
- 特徴3. 異なるデータ A と入力としたときハッシュ値 A' を出力するとしたら、 同じハッシュ値を生成するデータ B (データ A とは異なる入力) を探すのが困難。
-
⇒ 「a」のハッシュ値は「60b725f10c9c85c70d97880dfe8191b3」です。
このハッシュ値を生成するような「a」以外の入力データを探してみてください。
同じハッシュ値を見付けるのは論理的には可能ですが、 現実的な時間内では無理でしょう。ハッシュ値は 128bit ですから、ハッシュ値は 2^128 = 340282366920938463463374607431768211456 種類もあります。 「いろんなデータのハッシュ値をあらかじめ計算して、 そのデータとハッシュ値の対応を HDD に記録しおけばいいのでは?」 と思うかもしれませんが、2^128 個のハッシュ値だけ記録するにしても 4951760157141521099596496896 TB の容量が必要です。
署名は「finger print」とも呼びます。finger print を日本語訳すると「指紋」ですが、
- 人間がいれば指紋を採取できる
- でも指紋から人間を復元することはできない
- ある人間と同じ指紋を持つ別の人間を探すことは非常に難しい
ハッシュを使った署名の流れ
さて、本題である署名に話を戻しましょう。 「遅い」「データ量が多い」という欠点を解消するために、ハッシュを利用します。ハッシュを使った署名の流れを図 3 に示します。
- 送信者は、平文のハッシュ値を計算します。
- 送信者は、計算したハッシュ値を秘密鍵で暗号化します。
- 送信者は、「平文」と「暗号化したハッシュ値」を送信します。
- 受信者は、送信者の公開鍵を取り寄せます。
- 受信者は、「取り寄せた公開鍵」で「暗号化したハッシュ値」を復号化します。
- 受信者は、「受信した平文」のハッシュ値を計算します。
- 受信者は、「復号化したハッシュ値」と「平文のハッシュ値」を比較します。 両者が一致すれば署名は正しいことがわかります。
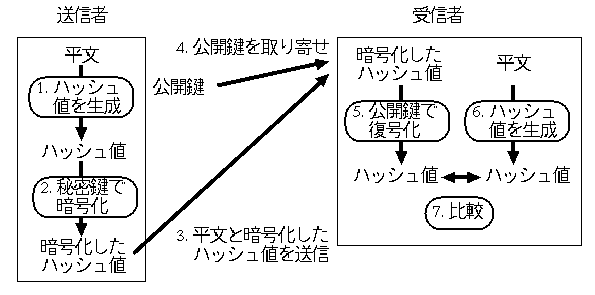 |
| 図 3: ハッシュを使った署名の流れ |
- 公開鍵暗号方式は遅い。平文全部を暗号化すると、かなりの時間がかかる。
- ⇒ 公開鍵暗号方式で暗号化するのはハッシュ値だけです。 ハッシュ値は 128〜512 bit 程度なので、公開鍵暗号方式が遅いといっても それほど時間はかかりません。
- 平文と暗号文を送信すると、データ量が約 2倍になる。
- ⇒ ハッシュを利用すると、平文と「暗号化したハッシュ値」を送信するようになります。 ハッシュ値は 128〜512 bit 程度なので、暗号化しても同程度のサイズになります。 よって、データ量は「平文 + 128〜512 bit」となります。
| 前へ << 暗号化のお話 (2) | 暗号化のお話 (5) >> 次へ |
ご意見・ご指摘は Twitter: @68user までお願いします。